MultiSphere: Consistently parallelizing high-dimensional sphere decoders
Start date
01 October 2015End date
15 December 2016Overview
Targeting a theoretical and practical framework for efficiently parallelizing sphere decoders used to optimally reconstruct a large number of mutually interfering information streams.
Sphere decoding is a well-known technique that dramatically reduces the related complexity. However, while sphere decoding is simpler, compared to other solutions that are able to deliver optimal performance, its complexity still increases exponentially with the number of interfering streams, preventing the practical throughput gains from being scaled by increasing the number of mutually interfering streams as predicted in theory.
This research targets practical sphere decoders able to support a large number of interfering streams with processing latency or power consumption requirements which are orders of magnitude smaller than those of single processor systems.
Paradigm shifts
This project is about targeting pragmatic future wireless systems able to deliver the capacity scaling predicted in theory, the proposed research focuses on two paradigm shifts that have a strong potential to transform the way we design wireless communications systems.
First paradigm shift
The one from orthogonal to non-orthogonal signal transmissions according to which, instead of trying to prevent transmitting signals from interfering, we now intentionally allow mutually interfering information streams.
Second paradigm shift
The one from sequential to parallel (receiver) processing according to which instead of using one processing element to perform the calculations of a functionality, we now split the corresponding processing load onto several processing units.
While digital processing systems with tens or even hundreds of processing elements have been predicted, it is still not obvious how we can efficiently exploit this processing power to develop high-throughput and power efficient wireless communication systems, and specifically how we can cope with the exponentially computationally intensive case of optimally recovering a large number of (intentionally) interfering information streams.
Acknowledgements
The research leading to these results has been supported from the UK’s Engineering and Physical Sciences Research Council (EPSRC Grant EP/M029441/1) and the 5G/6G Innovation Centre within the Institute for Communication Systems, University of Surrey.
Funding
The research leading to these results has received funding from the European Research Council under the EU’s Seventh Framework Programme (FP/2007-2013), ERC Grant Agreement number 279976.
Funding amount
£98,465
Team
Principal investigator

Dr Konstantinos Nikitopoulos
Reader in Signal Processing for Wireless Communications
Biography
Dr Nikitopoulos is currently a reader, within the Institute for Communication Systems, University of Surrey, UK, and the Director of its newly established “Wireless Systems Lab”. He is an active academic member of the 5G Innovation Centre (5GIC) where he leads the “Theory and Practice of Advanced Concepts in Wireless Communications” work area.
Collaborators

Professor Kyle Jamieson
External collaborator
Biography
Dr Jamieson received BSc and MEng degrees in computer science from the Massachusetts Institute of Technology, USA, and a PhD in computer science, from the same university, in 2008.
He is currently an Associate Professor with the Department of Computer Science, Princeton University, USA, and an Honorary Reader with University College London, UK. His research focuses on building mobile and wireless systems for sensing, localisation, and communication that cut across the boundaries of digital communications and networking.
He received the Starting Investigator Fellowship from the European Research Council in 2011, the Best Paper awards at USENIX 2013 and CoNEXT 2014, and the Google Faculty Research Award in 2015.
Graduate students and engineers
- Georgios Georgis - Senior Researcher
- Christopher Husmann - Researcher
- Chathura Jayawardena - Researcher
- Nauman Iqbal - Researcher
- Daniel Chatzipanagiotis - Alumnus.
Outputs
Complexity and throughput
Linear detection approaches offer low latency and complexity, but can result in a highly sub-optimal throughput. Maximum likelihood detection on the other hand, allows to scale the throughput with the number of antennas, at the cost of exponentially increased complexity beyond the capability of current processor architectures.
Based on a novel metric of promise, this project estimates the probability of a node in the tree search to be part of the transmitted vector and then, depending on the number of available processing elements, partitions the sphere decoding tree search into subtrees which preserve maximum likelihood optimality and can be processed in a nearly concurrent manner.
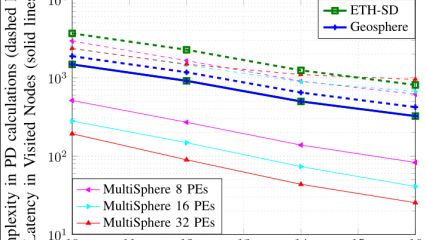
In single-carrier detection with 32 available processing elements, we can reduce latency by more than an order of magnitude compared to state-of-the-art sequential sphere decoders and maintain a similar computational complexity. Additionally, in the high SNR regime, our latency with 32 processing elements is close to that of linear detection methods (i.e., the number of transmitting antennas).
Complexity is measured in terms of partial distance calculations, latency measured in terms of visited nodes - 8 x 8 MIMO, 10-16dB SNR, 16-QAM uncoded transmission, SD partitioning based on the exact transmission channel.
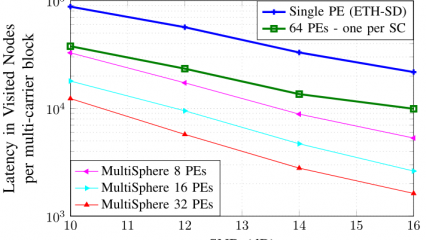
In multi-carrier detection when we consider the amount of available processing elements to be up to the number of subcarriers, one could perform detection by allocating a sequential sphere decoder per subcarrier and process the subcarriers in parallel.
We can instead employ a single MultiSphere detector to process the subcarriers in a sequential manner. In this case, an 8-PE MultiSphere detector decreases latency by a factor of 3, while a 32-PE MultiSphere detector achieves more than one order of magnitude reduction in latency.
Latency measured in terms of Visited Nodes - 8 x 8 MIMO, 10-16dB SNR, 16-QAM uncoded transmission of 64 subcarriers.
While MultiSphere can obtain the exact maximum likelihood solution by visiting a significantly decreased number of nodes compared to sequential SDs, its latency can significantly vary, depending on the SNR and the channel condition.
MultiSphere's search can be terminated at any time instant, therefore flexibly providing a tradeoff between ML optimality and detection latency. FlexCore is MultiSphere's sub-optimal version which considers only as many paths as the number of available processing elements.
FlexCore has been evaluated using both over-the-air experiments and simulations on channel traces, using the WARP v3 SDR platform and WARPLab (REF). Experiments have been conducted in an indoor environment employing 20 MHz carrier bandwidth within the 5 GHz ISM band.
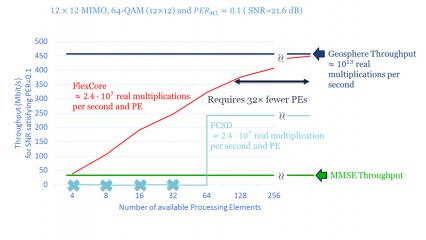
In contrast to similar, state-of-the-art solutions like the Fixed-Complexity Sphere Decoder, FlexCore can flexibly scale the achievable throughput depending on the number of available processing elements. Moreover, it can reach near optimal performance with more than one order of magnitude fewer processing elements.
Processor speed and lithography
Based on the 2015 International Technology Roadmap for Semiconductors, transistors can stop shrinking and thus cease becoming faster by as soon as 2021. Thus, a paradigm shift from sequential to parallel processing is required.
By exploiting multiple processing elements (PEs) per single die, research can lead to high-throughput MIMO systems.
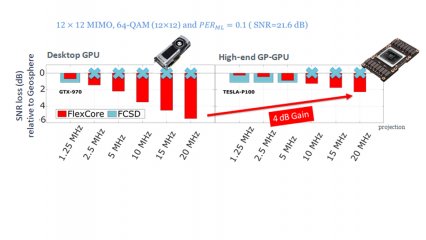
FlexCore is flexible enough to achieve real-time detection for all LTE modes on a commercially available desktop general purpose graphics processing unit (GPU), compared to the fixed-complexity sphere decoder, which requires a fixed number of tree paths.
And given a more powerful GPU, FlexCore can employ more tree paths and thus achieve a performance which is even closer to that of optimal detection. (All results include Host to GPU and GPU to Host memory transfers, assuming a 10ms frame duration).
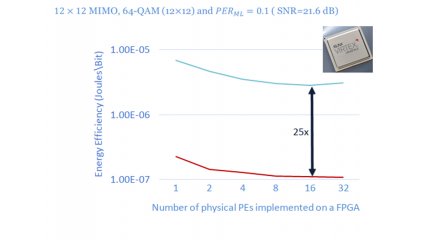
FlexCore's probabilistic tree path allocation and the direct control over hardware resources, allow for achieving more than one order of magnitude higher energy efficiency, compared to the fixed-complexity sphere decoder, i.e. the similarly parallelizable state-of-the-art.
(Xilinx Virtex Ultrascale 440-flga2892-3-e, Xilinx Power Estimator under worst-case static power and 100 per cent activity, 75 per cent maximum logic slice utilisation).