
Impact and news
PAI is a thriving research community engaged in cutting edge research and events. We bring together AI leaders from academia, Government and industry. Our events include workshops, international conferences, showcases and networking opportunities addressing the technology and societal impact of AI.
A slice of PAI: News from the Institute

We are immensely proud of CVSSP first-year PhD researcher, Jian He Low, who has won the Best Paper Award at the ICCV 2025 Workshop—an extraordinary achievement for a student researcher on the global stage. Jian He’s award-winning paper, “SAGE: Segment-Aware Gloss-Free Encoding for Token-Efficient Sign Language Translation,” represents a significant step forward in the fields of computer vision and sign-language translation. Such an award is a significant achievement for a first-year PhD researcher. It highlights the quality and contribution of Jian He’s work, and is testament to the dedication of CVSSP researchers and the collaborative environment the Centre fosters. Congratulations to the entire supervision team, including Professor Richard Bowden and Dr. Özge Mercanoğlu Sincan, for their outstanding guidance and support.

The winning paper presented by first-year researcher Joan Amaya Cuesta offers a swift, novel approach to virus classification. Joan won first place at Rabies In The Americas (RITA), the most prestigious international scientific conference in the rabies field. Beyond rabies, the approach sets a template for automating cell-culture assays more broadly, improving reliability and accessibility in low-resource settings.
Joan is conducting his doctoral research with Professor Mirek Bober and Dr Syed Sameed Husain at CVSSP and PAI. The research is also in collaboration with the UK Government’s Animal & Plant Health Agency (APHA) under the supervision of Dr Lorraine McElhinney and Dr Guanghui Wu.
Joan’s award-winning paper, "Deep Learning Models for Rabies Virus Detection in Cell Cultures," presents the first AI system of its kind: a state-of-the-art vision transformer that classifies rabies virus infection directly from fluorescence microscopy images of cell cultures. The approach could revolutionise diagnostics, especially in low-income countries, by replacing subjective, labour-intensive reads with fast, scalable, and objective analysis. The system achieves near-perfect performance and aligns well with expert judgments on ambiguous cases.
Congratulations to Joan for this distinguished win: participants, chairpersons and area chairs recognised this innovative AI system as world-leading, noting that it has the potential to revolutionise rabies virus analysis and diagnosis. It marks a significant stride in diagnostic technology.
The innovation aligns strongly with key research tenets at both CVSSP and PAI, leveraging artificial intelligence to support people, the environment, and animal welfare. Rabies remains a fatal, zoonotic disease, and swift, accurate diagnosis is crucial for effective intervention and control. By using deep learning, the team aims to enhance the speed and reliability of laboratory testing methods.
The RITA Conference is the most important international scientific conference in the rabies field, bringing together researchers, veterinarians, and public health officials from around the globe.
For more information about RITA, visit: https://ritaconference.org/en/

A collaborative research team from CVSSP and the BBC has secured the prestigious Best Technical Paper Award from the Audio Engineering Society (AES) for their work on developing an AI-driven system to radically improve creative audio workflows.
The winning paper was co-authored by Haohe Liu, Dr Thomas Deacon and Professor Wenwu Wang from CVSSP, alongside Professor Mark Plumbley from Kings College, London, and Matt Paradis from Research and Development at the BBC in London.
The paper, "Exploring the User Experience of AI-Assisted Sound Searching Systems for Creative Workflows," was recognised at the 159th AES Convention in Long Beach, California. Haohe Liu attended the award ceremony on 23 October 2025.
The research addresses the time-consuming and often inaccurate process of finding the right sound effect. Traditional systems rely on pre-annotated labels – tags manually applied to audio clips – which can quickly become outdated or insufficient.
The team's solution bypasses this reliance on human labour by employing a concept known as contrastive language-audio pretraining (CLAP). Using this idea, the team built a CLAP-based sound searching system (CLAP-Search) that does not rely on human annotations. To evaluate its efficacy, they conducted comparative experiments with the BBC Sound Effect Library. The study demonstrated a significant boost in productivity and a marked reduction in frustration for users, while maintaining comparable cognitive demands. In short, AI can do the hard work, allowing human creators more time to create.

PAI and CVSSP's Professor Wenwu Wang, a leading figure in machine learning and audio processing, has had an extremely active season on the global conference circuit, cementing his status as a key influencer in the rapidly evolving world of AI-driven signal processing.
His involvement, ranging from chairing major international workshops to delivering keynote speeches on the future of sound and language models, showcases CVSSP and PAI's globally-leading* strengths in deep technical domains, aligned to its focus on people-centred AI.
Istanbul
Professor Wang's leadership was evident at the 35th IEEE International Workshop on Machine Learning for Signal Processing (IEEE MLSP 2025IEEE MLSP 2025IEEE MLSP 2025) in Istanbul, Turkey (August 31 - September 3). As the Technical Programme Chair, he was instrumental in shaping the academic agenda for one of the field's most important gatherings.
He also spearheaded the Industrial-Academic Joint Workshop on cutting-edge audio, speech, and language challenges, fostering essential dialogue between research and industry. Read more here.
The conference served as a platform for his research excellence:
His PhD student, Özkan Kılıç, presented a paper, co-authored with Dr Saeid Safavi (Professor Wang’s former postdoctoral researcher) detailing a novel dataset and framework for Drone Detection and Localisation using multi-channel audio - a crucial topic for security and airspace monitoring.
His former visiting student, Jinhua Liang, explored the challenging area of evaluating Text-to-Music systems, moving beyond basic aesthetics to focus on genuine human preferences.
London
Closer to home, Professor Wang brought his expertise to the 13th Computing Conference (Computing 2025) in London. He delivered a high-profile keynote address titled “Large Language-Audio Models and Applications,” diving into the next generation of AI that seamlessly processes both sound and text. Watch the slides here.
This talk, captured on video, highlighted the transformative potential of combining massive language understanding with sophisticated audio analysis - a frontier currently attracting huge research interest.
Nantes
Professor Wang’s collaborative spirit was in evidence at the IEEE International Conference on Multimedia & Expo (ICME 2025) in Nantes. Here, he co-organised the Audio Encoder Capability Challenge, pushing the state-of-the-art in how digital audio is processed and compressed - a fundamental technology underlying all modern streaming and communication.
He also contributed to the technical backbone of the conference, chairing two key sessions on "Domain Adaptation and Learning" and helping to present two papers “DCGNet: Detail and Context Guided Small Object Detection Network with Decoupled Detection Head” & “EMGPose: An Efficient Multi-Granularity Representation for Human Pose Estimation”, co-authored with his former academic visitor, Dr Shiyong Lan.
Rotterdam
Rounding out his busy season, Professor Wang attended the flagship speech technology conference, Interspeech 2025, in Rotterdam. He co-authored and presented with Dr Rohan Kumar Das (Fortemedia Singapore), a paper titled “EnvSDD: Benchmarking Environmental Sound Deepfake Detection”, addressing the serious, emerging challenge of detecting deceptive, AI-generated environmental sounds.
Professor Wang's busy and highly productive schedule underscores his pivotal role in the global conversation on signal processing and AI. His work is one of the keystones of the University of Surrey’s dominance* in tackling technical and societal challenges in machine perception.
*1st in the UK, 5th in Europe, and 23rd in the World for Computer Vision since records began [CSRankings.org, accessed 29 September 2025]

When PAI's Dr Bahareh R. Heravi founded the key international conference, European Data & Computational Journalism Conference (DataJConf) in Dublin in 2017, her vision was to create an important, open forum focused on ensuring that the growth of AI within newsrooms remains rooted in the tenet of being people-centred.
Since then it has gone from strength to strength, focusing the European conversation on the future of news. This year’s iteration in Athens, co-chaired by Dr Heravi, saw the largest gathering in the conference’s history, solidifying its place as the premier European event in the field. The line-up of keynote speakers included experts from Stanford University, Northwestern University and the BBC, with other speakers and panellists joining from renowned organisations such as the Financial Times, Bloomberg, Tamedia, Reach plc, DER SPIEGEL, APA - Austria Presse Agentur, and the International Consortium of Investigative Journalists (ICIJ).
Dr Heravi said: “When we launched this conference in 2017, my wish was simple: to create a space where journalists and academics could truly learn from each other. Eight years on, Athens showed us how powerful this exchange can be, and how vital it remains for the future of the field. I could not be prouder of the vibrant community we have become.”
The move to Athens, following previous successful iterations in Ireland, Britain, Spain, and Switzerland, underscores Dr Heravi’s commitment to diversity and broad European inclusion.
"It’s very important to me that the conference is shaped by a broad range of voices, and not limited to the usual dominant players who typically shape the space. One way we’ve tried to achieve this is by rotating the conference between northern/western and southern/eastern Europe. This helps broaden participation, makes it easier for researchers and practitioners from across the continent to contribute, gain visibility on the international stage, and help shape the field both locally and globally.
"We also have an exceptional programme committee with members from across Europe and internationally. I am grateful that they have graciously accepted my invitation to join over the years, forming a distinguished group of experts whose insight and commitment to the peer review process consistently shape a programme that underpins the quality and diversity of perspectives at the conference programme," Dr Heravi explained.
Two researchers from PAI’s UKRI Centre for Doctoral Training in AI for Digital Media Inclusion (CDT) joined Dr Heravi at the conference; Karyn Fleeting and Weiwei Jin. Karyn sat with Dr Heravi on two panels (representing Reach Plc, for which she is the AI Delivery Director), and Weiwei helped with the sessions.

Save the date! 📅 PAI Director and Founder, Professor Adrian Hilton, has been invited to contribute to the British Safety Council Conference on 14 October 15:40-16:25 as a guest speaker and panel member talking about the impact of AI in the workplace.
Professor Hilton is looking forward to a productive day of insights, discussing the key topics of safe, ethical and people-centred AI. He will focus on how we can upskill people and bring them with us, as AI transforms how we work.

We proud to announce that our Co-Director, Professor Yi-Zhe Song and his team have made another landmark achievement in generative AI! 🚀
Together with Stability AI, they have announced SD3.5-Flash, a new model that brings high-quality, private, and local image generation directly to consumer devices, even our iPhones! This breakthrough continues the mission of SketchX lab to democratise creative AI, building on their previous projects like NitroFusion and DemoFusion.
SD3.5-FLASH is built on two key innovations:
- Timestep Sharing: a technique the research team developed that provides stable gradient signals and improves training stability.
- Split-Timestep Fine-Tuning: a method designed to improve prompt-image alignment by temporarily expanding model capacity during training.
This project was led by Professor Song's student researcher, Hmrishav Bandyopadhyay, during his internship at Stability AI. Professor Song said: "This is a perfect example of how industry and university collaboration can push the boundaries of AI, scaling academic innovation for real-world impact."

⭐ We are thrilled to announce that PAI and CVSSP's Dr Armin Mustafa has been named as a winner of the Tech Women 100 award in 2025. Dr Mustafa said:
"I am honoured to be named a TechWomen100 winner. For me, this award reinforces that our work is to create a better and innovative future. I hope this recognition inspires other women to pursue their passions in technology, knowing that their contributions are not only valued but essential. A huge thank you to my mentor and colleagues at the University of Surrey for their support, and WeAreTheCity for this incredible initiative."
Read about Dr Mustafa's incredible achievements here

We are delighted to announce that our PAI Fellow, Professor Nishanth Sastry, along with our Surrey colleagues Professor Professor Ravi Silva FREng CBE, Harris Dellas, Ali Emrouznejad, Ian Brunton-Smith and Director, Research, Innovation and Impact, Gillian Fairbairn have been appointed as panel members for 2029 The Research Excellence Framework (REF).
All six members of the Surrey community will play a vital role in assessing the quality of UK research and influencing how research funding will be spent.

PAI's PGR researcher Archchana Sindhujan and Dr Diptesh Kanojia, and Professor Constantin Orasanăsan from our Centre for Translation Studies are bridging a critical gap in machine translation, creating the first-ever dataset to improve the quality of English-to-Malayalam translation.
Despite being spoken by over 38 million people, Malayalam is considered a "low-resource" language in the world of machine translation, with no existing data for evaluating the quality of translations from English. This new project, funded by the European Association for Machine Translation, changes that.

PAI’s Dr Erick Sperandio has co-authored a groundbreaking study on the application of quantum neural networks (QNNs) for wind speed forecasting. Dr Sperandio and his colleagues from the Quantum Industrial Innovation (QuIIN) at Universidade CIMATEC, Brazil, suggest that quantum computing offers a significant "green quantum advantage," capable of performing certain tasks with up to 10,000 times less energy than conventional supercomputers. This approach positions quantum AI as a promising tool for tackling climate-related and clean energy challenges. Read the study here 👉sciencedirect.

Our researchers have developed a new AI system that could change how autonomous vehicles navigate without GPS, narrowing down localisation errors from 734 metres to within 22 metres. In a paper published in IEEE Robotics and Automation Letters, Dr Simon Hadfield (pictured) and PhD researcher Tavis Shore describe PEnG (Pose-Enhanced Geo-Localisation), a technology that combines satellite and street-level imagery to determine location using only visual data. In environments where GPS signals are weak or obstructed, such as tunnels, big cities and regions with poor connectivity, PEnG offers a reliable and precise alternative for navigation.
Tavis and his team are now focused on building a working prototype, supported by the University of Surrey's PhD Foundership Award, which funds early-stage development of the proposed GPS-free navigation device.
https://www.surrey.ac.uk/news/new-ai-system-could-change-how-autonomous…
We are recruiting a Professor in Machine Learning and AI with a focus on Large Machine Learning Models to expand our dynamic team of internationally recognised AI researchers. This is part of a strategic investment of 6 posts across the School in AI, Cyber Security and Satellite Communications, which also incorporates a Lectureship to support this position. You'll lead ground-breaking research within our top-tier AI community, ranked 1st in the UK for Computer Vision and Top 5 for AI (CSRankings.org). Learn more and apply here:
039425 Professor in Machine Learning and AI - Jobs at the University of Surrey
Join our world-leading Centre for Vision, Speech and Signal Processing at University of Surrey (CVSSP), where we are recruiting a full-time lecturer in Robotics to expand our team of dynamic and highly skilled AI faculty and researchers. CVSSP and Computer Science are at the core of PAI. Surrey has an established international track record in AI research, 1st in the UK for computer vision and top 5 for AI, computer vision, robotics, machine learning and natural language processing (CSRankings.org) and 7th in the UK for REF2021 outputs in Computer Science research.
http://jobs.surrey.ac.uk/039825

July 21, 2025
Congratulations to PAI’s Dr Erick Sperandio (pictured), who with international colleagues, has secured a significant award from the University Global Partnership Network (UGPN)'s Research Collaboration Fund (RCF). Their ground breaking research proposal, "BREATH-AI - Breathing Through Fire: Unravelling Wildfire Pollutant Dispersion and Health Impacts with AI", was one of just six selected from a competitive field of 28 submissions.
This important project, led by PAI at the University of Surrey, will be a trilateral collaboration with the University of São Paulo and North Carolina State University.
The project will use AI models to predict how wildfire smoke affects air quality and health in towns and rural areas. It will examine specific examples in Brazil, the UK, and the USA. This will help researchers understand who is most at risk, enabling planning to mitigate the risks. The project will run from August 2025 to January 2027.
Dr. Sperandio expressed his gratitude: "Many thanks to all partners, especially to my co-PIs Marco Franco and Katia Fernandes, and to PAI, NVIDIA, MedSênior, and Guildford Borough Council for their invaluable support."
This achievement highlights PAI’s commitment to impactful research and international collaboration in addressing critical environmental and health issues. Congratulations to Dr. Sperandio and his team on this outstanding recognition!

The UK’s new Compute Roadmap, announced by the Department for Science, Innovation and Technology, aims to strengthen the nation’s high-performance computing capabilities and workforce, with the University of Surrey chosen to host one of two national training hubs in a bid to close the gap in critical skills.
The Hub’s Surrey home brings vital benefits to the new venture: the University is a driving force in AI through its Institute for People-Centred AI (PAI) and Centre for Vision Speech and Signal Processing (CVSSP). The University’s ranking of 1st in the UK for Computer Vision since records began derives from CVSSP’s research. CVSSP’s Dr Helen Cooper (pictured) will serve as the Principal Investigator for the ACIT Hub.
The Accelerated Compute Infrastructure Training Hub (ACIT-Hub) has secured £3.9 million in funding, with a majority share awarded by UK Research and Innovation (UKRI) to deliver personalised, industry-recognised training for Research Technology Professionals (RTPs). Unlike traditional research grants, this initiative is almost entirely RTP-led.
“Accelerated compute infrastructure is technology that speeds up large computing tasks and it forms the bedrock of the burgeoning world of AI. This hub is about investing in people – giving them the skills, recognition and professional development opportunities they need to help the UK fully realise the potential of accelerated computing.” - Dr Helen Cooper
Dean Roe, Co-Investigator for the Hub and Dr Jaydeep Mody from Research Computing Services were instrumental in securing the bid alongside Dr Cooper, highlighting the expertise supporting the venture at the University.
“The ACIT-Hub is led by Research Technology Professionals and will draw upon our collective knowledge and experience of the real-world challenges of supporting and delivering the technologies and systems underpinning accelerated compute. The Hub will offer practical, high-quality training that meets the needs of our community. We’re proud that Surrey is leading this effort to strengthen the UK’s computing capabilities and support the next generation of technical experts.” - Dean Roe
Secretary of State for Science, Innovation, and Technology Peter Kyle said: “Britain has top of the class talent in AI and our plan will put a rocket under our brilliant researchers, scientists, and engineers – giving them the tools they need to make Britain the best place to do their work. This will mean we can harness the technology in Britain to transform our public services, drive growth, and unlock new opportunities for every community in the country.”
The ACIT-Hub is partnering with other leading universities; Oxford, Sheffield, Imperial and Bristol, and draws on networks such as the UKRI Tier 2 JADE consortium to deliver coordinated, industry-relevant training and support the UK’s accelerated computing goals.
PAI’s founding tenet in 2021 was to put people at the heart of AI. PAI delivers trustworthy, people-centred advancements that touch every facet of our lives; revolutionising healthcare, education, sustainability, creativity, information, entertainment and social inclusion.

PAI and CVSSP are immensely proud of the latest revolutionary breakthrough from our SketchX Lab, led by our Co-Director Professor Yi-Zhe Song: the groundbreaking NAG (Normalized Attention Guidance), a project led by PhD student Dar-Yen Chen. NAG is a technical leap that makes generative AI (especially diffusion models) far more practical and controllable for creators and developers, allowing them to quickly generate high-quality, precisely guided content.
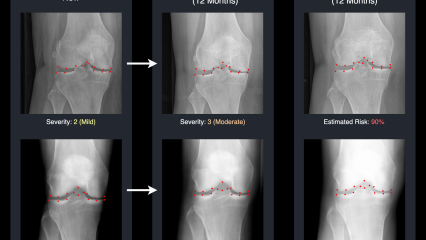
Supervised by PAI and CVSSP’s Professors Adrian Hilton and Gustavo Carneiro, PhD researcher David Butler has produced an important paper on how AI can improve osteoarthritic knee care. This is an important leap towards more personalised, anticipatory care, using AI not just to predict but to communicate future health states in a proactive way. The paper has recently been accepted to MICCAI, the leading medical image analysis conference, as being in the top 9% of the submissions, a huge accomplishment in itself.
But the researchers see the potential effect on patient outcomes as their greatest achievement.

PAI Director Dr Andrew Rogoyski was invited to speak recently at the The Alan Turing Institute’s Centre for Emerging Technology and Security (CETaS) annual showcase. This inspiring event covered key issues of AI security.
“The reason why [the UK is] an AI superpower is because of our talent, ideas and academic sector. That’s what will keep our top three spot in the AI superpower ranking, so we must really think very hard about how we protect our knowledge,” Dr Rogoyski commented during the panel, ‘AI and Research Community.’
📽️ Watch the insightful and engaging panel: AI and Research Security – CETaS Annual Showcase 2025 - YouTube
"Moving forward, it is imperative to develop and deploy more sustainable and people-centred AI solutions that are less resource-hungry while continuing to deliver superior performance.”
Important commentary from PAI's Dr Erick Sperandio, Programme Lead of AI and Sustainability, in which he discusses the escalating sustainability challenges associated with Artificial Intelligence (AI), with its growing environmental and societal impact: 🔗Are we ignoring AI's sustainability problem?

PAI and CVSSP’s Professor Gustavo Carneiro (pictured middle row, right hand side) and two PAI Fellows are playing leading roles in the new ambitious research partnership between The University of Surrey and The University of Adelaide, set to accelerate progress in space, AI, sustainability and cybersecurity.
Professor Carneiro, with his Adelaide counterpart, Dr Yuan Zhan are Principal Investigators (PI) in ‘Advancing AI-driven diagnostic tools for Endometriosis’.
PAI Fellow Professor Jin Xuan, with Adelaide counterpart, Professor Kannan Govindan are PI on another of the eight prestigious projects: ‘Exploring the challenges and opportunities of sustainable supply chain in Space circular economy’.
PAI Fellow, Professor Nishanth Sastry, with Adelaide co-PI, Professor Matthew Roughan, will be exploring a third project in the series: ‘Assessing the Communications Performance of Massive Satellite Systems’.
Congratulations to all participants in this ground breaking series of advances that demonstrate the power of international research cooperation.

His Royal Highness, The Duke of Kent, Chancellor of the University of Surrey hosted a fantastic event at Windsor Castle to celebrate the remarkable success of The Future Says Surrey campaign. Raising an incredible £70.3 million, this initiative will drive groundbreaking research and open doors for students from all backgrounds to excel at Surrey.
Pictured (L-R) Professors Ravi Silva, Jim Al-Khalili and Adrian Hilton (Director of PAI)

Between 24 and 27 March 2025, 30 UK scientists swapped places with politicians and civil servants, exploring the world of politics as part of the annual Royal Society Pairing Scheme.
PAI Fellow Professor John Collomosse participated in the Scheme, working directly with the Department for Science, Innovation and Technology's team for policy and capability in AI and Disinformation. This vital initiative helps ensure evidence-based policymaking. Professor Collomosse's expertise, honed through DECaDE and his work in the formation of the Content Authenticity Initiative, will be invaluable. A fantastic opportunity to amplify our research for the public good.

Watch PAI Fellow and Professor of Safe AI and Autonomy, Saber Fallah as he features in the first of a series of films 🎥by The Alan Turing Institute, with Innovate UK BridgeAI: Capsules of AI Knowledge. The series helps SMEs navigate the five stages of AI adoption.

In an initiative led by Professor John Collomosse (pictured), PAI is contributing to a significant new research initiative aimed at advancing responsible AI within the creative sector. This project, "Performance, Participation, Provenance and Reward in Responsible AI (P3R)," is part of the Arts and Humanities Research Council’s (AHRC) Bridging Responsibilities AI Divides (BRAID) programme.
Led by Royal Holloway, University of London (RHUL) and the CoSTAR National Lab, P3R is exploring how responsible AI tools can foster equitable opportunities for creatives and enhance environmental resilience. PAI's involvement underscores our founding tenet; to ensure AI development prioritises people-centred values and societal good.
“P3R builds upon DECaDE’s multi-year research programme in media provenance, teaming up with practice-led research in the CoStar National Lab to create new tools for fairly recognising and rewarding musicians for the re-use of their live performance. This will help ensure an equitable creator economy in the face of advances in AI.” Professor John Collomosse
Working alongside colleagues within RHUL, Abertay University, and The National Film and Television School, Professor Collomosse’s team is contributing to the development of a demonstrator that harnesses research out of the Surrey-led DECaDE research centre to put innovative tools for content rights and monetization into the hands of musicians. This initiative aims to help them discover new audiences and address the challenges faced by grassroots music venues across the UK.

The Alan Turing Institute's new report, Securing the UK’s AI Ecosystem, represents a significant step towards shaping the UK's AI landscape. We're delighted that PAI's Dr Andrew Rogoyski was asked to contribute his expertise. His comments and suggestions have helped to inform this timely, must-read document.
Really pleased to see the The Alan Turing Institute publish this report on the concerns that nation states may be targeting the UK's academic capabilities in AI (and glad to have been involved in its creation). It's a complex topic with competing interests, nonetheless it's an area that needs more airtime. Dr Andrew Rogoyski

Huge congratulations to Dr Cuong Nguyen, Professor Gustavo Carneiro (pictured), and their Monash University collaborator, Dr Toan Do, on the acceptance and selection for oral presentation at ICLR 2025 of their paper, "Probabilistic Learning to Defer: Handling Missing Expert Annotations and Controlling Workload Distribution." Only 1.8% of ICLR submitted papers are selected for an oral presentation, so this is a well-deserved great honour.
This paper is a significant contribution from the EPSRC-funded People-Centred Mammogram Analysis (PecMan) project. It tackles the crucial challenge of developing AI models that can intelligently defer mammogram classifications to radiologists when uncertain.
We're hugely proud of the team for their ground-breaking work. We look forward to their presentation at ICLR 2025.
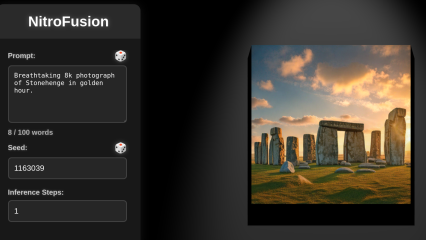
A ground-breaking AI model that creates images as the user types, using only modest and affordable hardware, has been announced by PAI and CVSSP's research lab, SketchX.
PAI Co-Director Professor Yi-Zhe Song, who leads SketchX, presented the world's first AI model for near-instant Image Creation on consumer-grade hardware: NitroFusion. It's the first-of-its-kind text-to-image that generates pictures as the user types – all using home-computing capabilities. And it is Open Source! Read more

In January 2025, PAI welcomed a delegation from the Department for Education (DfE), led by Julia Kinniburgh, Director General of the Skills Group. The group was hosted by our Director, Professor Adrian Hilton, and Co-Director, Professor Yi-Zhe Song. Professor Hilton provided an overview of how Surrey is leveraging its 40-year heritage to embrace the ambitions set out in the AI Opportunities Action Plan.

PAI co-director Professor Yi-Zhe Song’s research, Chirpy3D is an AI system that lets one create novel birds in 3D with unprecedented creative control. It pushes the boundaries of fine-grained 3D generation into truly creative territory. Current methods either lack intricate details or simply mimic existing objects - Chirpy3D enables both. This is the first system capable of creating novel 3D objects with species-specific details that transcend existing examples. Read more here

Congratulations to the researchers of PAI and CVSSP on their momentous recent conference and publication achievements
Over the world and over the years, their work is the pillar behind our no. 1 in computer vision ranking since records began – CS Rankings, retrieved 31 October 2024: tinyurl.com/5n8zs5yh
We are immensely proud of their record of publishing impactful papers and presenting at prestigious conferences. Their hard work, dedication, and ground-breaking ideas are inspiring.
These are some of their recent conference achievements that we are celebrating: https://tinyurl.com/33tcuca7





Impact and policy
About the University of Surrey’s Institute for People-Centred AI and DECaDE
The Surrey Institute for People-Centred AI (PAI), launched in November 2021, builds on the nearly 40-year history of CVSSP (Centre for Vision, Speech and Signal Processing), the UK’s leading AI machine perception research group. The Institute promotes a people-centric approach to AI development, starting with the problems that face humanity, societies and individuals, identifying how AI can be leveraged to solve these challenges. As a pan-University Institute, PAI combines strengths across Surrey’s research centres to foster interdisciplinary solutions to complex problems. Collaboration with industry, policymakers and other institutions is a core capability. Examples of current high-profile projects include the AI4ME Prosperity Partnership with the BBC, and the UKRI Centre for Doctoral Training in AI for Digital Media Inclusion.
DECaDE is the UKRI Centre for the Decentralised Digital Economy, a multidisciplinary research centre led by the University of Surrey in partnership with the University of Edinburgh and the Digital Catapult. DECaDE is funded 2020-2026 by the UKRI/EPSRC. DECaDE’s mission is to explore how decentralised platforms and data centric technologies such as AI and Distributed Ledger Technology (DLT) can help create value in our future digital economy in which everyone is a producer and consumer of digital goods and services. DECaDE studies these questions primarily through the lens of the creative industries, which have shifted from monolithic content producers to a decentralised model where individuals and smaller production houses also increasingly produce and consume content disseminated via online platforms. As a multidisciplinary academic research centre, DECaDE brings together technical expertise in AI, DLT and Cyber security, with business, law, and human factors/design. DECaDE co-creates its research with over 30 commercial partners including several in the creative sector including Adobe and the BBC, and has worked extensively with the Cabinet Office and Scottish government.
Together we are delighted to respond to the UK Government’s consultation on AI and Copyright. N.B. DECaDE has also responded as an individual group to this consultation.
The UK context
The UK Government’s view, as set out in the AI Opportunities Plan, is that the AI revolution is radically changing how we live, work, and operate as a society and that it is incumbent on Government to work with partners in industry and academia to play a shaping role in where this future takes us.
The creative industries, one of the fastest growing sectors in the UK, has a critical role to play in the Government’s growth ambitions. The Copyright and AI consultation is an important part of the policy process to ensure that the UK’s creative IP, at an individual, collaborative and country level is protected and valued as we seek to grasp the benefits that AI can bring.
Indeed, it is in the interests of future AI systems to protect human creativity. Without it, the incentives for humans to create content which delights other human beings but may also be used to train ever more advanced AIs, decays away. Not only would this leave society poorer but the decline in human-inspired content would leave less material for training next generation AIs, which, combined with the rapidly growing volume of AI-generated content that is shared on the internet, may lead to “model collapse” as AIs are increasingly trained on their own data. This would lead to the eventual failure or plateauing of AI capabilities. In other words, we need to preserve the value of human content creation to support the future capabilities of AI.
The UK is well placed to play a leading role in shaping the future developments of AI. Stability and assurance are core components. Investors are attracted by business environments with good stable markets, protected by disciplined and well-tested legal systems, and access to high quality talent, all of which the UK has. Emerging AI and copyright tensions will need to be managed in a way that supports our ability to offer clarity and stability.
UK wealth and economic growth does not necessarily stem from “Big Tech” AI platforms like OpenAI, rather through the application of AI technologies in traditional industries, including the creative sector and extending to areas as diverse as aerospace, manufacturing and healthcare. The UK’s advantage will not stem from a race to the bottom in terms of being permissive about use of data for AI, instead from the creation of clear, consistent and will-implemented rules that guide the development and application of AI, ensuring that the UK economy and UK citizens are at the heart of future AI developments.
Recommendations
1. Support Data Mining Exception with Transparency
The UK should adopt Option 3, which offers a data mining exception allowing right holders to reserve their rights, supported by transparency measures. This approach would protect creators' rights while promoting large-scale data access essential for AI development, thus enhancing the UK's global competitiveness.
2. Introduce Granular Opt-Out Mechanisms
The government should implement a more nuanced opt-out system for creators. This would enable content owners to specify the types of AI processes from which they want to opt out, such as generative AI, while still permitting use for less intrusive purposes like content classification or search, noting that such granularity should not place unnecessary burdens on the content creators, in terms of understanding or applying such mechanisms.
3. Adopt Standardised Machine-Readable Markers for Rights Reservation
A standardised, machine-readable system (like C2PA) should be introduced to indicate content usage restrictions, ensuring that developers can easily identify whether data is off-limits for AI training. This would facilitate widespread, frictionless compliance and protect creators' rights across platforms.
4. Ensure Transparency and Due Diligence in AI Training
The system should require AI developers to take responsibility for respecting creators' opt-out reservations, including incorporating transparent metadata and performing due diligence. While it should not be expected that developers search the entire internet for opt-out content, they should ensure their systems handle the metadata appropriately.
5. Consider Retraining AI Models for Infringement
In cases where a rights reservation is ignored, legal remedies should be expanded to include the requirement for AI developers to retrain their models without infringing content.
6. Encourage the Adoption of Open, Patent-Free Standards for Rights Reservation
The UK government should endorse open standards, like C2PA and TDMRep, for rights reservation and provenance metadata. These standards will allow for seamless interoperability across industries while respecting intellectual property rights. By avoiding mandating a single proprietary approach, the government can foster innovation and flexibility in the rights management ecosystem, recognising that future AI developments may require such approaches to be adapted and updated.
7. Strengthen Legal Significance of Metadata and Rights Reservation
Compliance with metadata and rights reservation protocols should be legally significant. Platforms should be encouraged to avoid removing markers carrying AI labels, provenance and rights information (such as C2PA) unless necessitated to preserve individual or group safety and security. For particular verticals such as news websites the government could introduce legislation to enforce the retention of metadata for AI-generated works to ensure transparency, accountability, and respect for creators’ rights, while allowing for necessary privacy controls. In other circumstances including creative use cases it may not always be desirable to implement AI-generated content labelling. Collaboration between government, academic and industry is necessary to further map this space and to raise welcome debate about whether non-compliant media should be blocked, acknowledging concerns over censorship and security.
8. Support Collective Licensing Systems for AI Data
The UK government should incentivise the use of Extended Collective Licensing (ECL) schemes, like those used in Nordic countries, to help AI developers and data owners navigate the complexities of obtaining content licenses. This would encourage fair compensation for creators while facilitating access to large datasets for AI training. Clear, transparent standards for participation and representation in CMOs (Collective Management Organizations) should be introduced to address any potential misuse of the system.
9. Clarify Copyright Protection for Computer-Generated Works (CGWs)
The UK should maintain its current protection for CGWs, ensuring that AI-generated works have copyright protection. Clear legislative guidance should be provided to prevent ambiguity about the originality requirement for CGWs. This would provide legal certainty to businesses and encourage investment in creative AI systems, ensuring that CGWs are appropriately recognised and protected.
Consultation responses
B. Copyright and AI
B.4 Policy Options
1. Do you agree that option 3 - a data mining exception which allows right holders to reserve their rights, supported by transparency measures - is most likely to meet the objectives set out above?
Yes
Comments:
Any amendments to copyright and IP protection should adopt the principle of protecting the work and livelihood of human artists and content creators; minimise the overhead of applying protections by the human artist or content creator; minimise the disputability (and associated costs) of infringements; maximise the economic growth potential for human artists, content creators and UK AI companies.
We believe Option 3, on balance offers a solution that offers a people-centred approach, upholding creators’ rights while facilitating the large-scale data access needed for AI development.
2. Which option do you prefer and why?
• Option 0: Copyright and related laws remain as they are
• Option 1: Strengthen copyright requiring licensing in all cases
• Option 2: A broad data mining exception
• Option 3: A data mining exception which allows right holders to reserve their rights, supported by transparency measures
We prefer Option 3 because it prevents the added friction that an opt-in or licensed-only model would impose on research activities, especially for academic and startup ventures. AI training at scale requires access to large and diverse datasets. If creators were required to opt in—or if restrictive licensing were the only route—many smaller research teams would be unable to clear rights sufficiently quickly or at scale. This would slow progress, reducing the competitiveness of UK-based academia. In addition, Option 3 aligns with existing EU legislation i.e. the text and data mining (TDM) exception within the EU Copyright Directive, Article 4. Taking a stance that is less permissive (such as Options 1 and 2 in the consultation) would make the UK less competitive for AI research and commercial activity, than the EU.
C. Our Proposed Approach
C.1 Exception with rights reservation
3. Do you support the introduction of an exception along the lines outlined above?
Yes
4. If so, what aspects do you consider to be the most important? If not, what other approach do you propose and how would that achieve the intended balance of objectives?
The transparency and the granularity of the exception (opt-out), as well the level of due diligence required by researchers would be the most important.
Granularity: Allowing creators to specify the kinds of AI processes from which they want to opt out is important, and a feature that is absent in the TDM exception within the EU Copyright Act, which resembles the spirit of Option 3 but was written prior to the advent of Generative AI.
For example, a creator might be willing to have their content used for AI models that classify, enable the search of content, and recommend content. However they might be unwilling to have their content used to train a generative AI model i.e. a model that creates derivative content from their content. Other creators might take a different view. It is our experience that creators would appreciate this level of granularity in opt-out. The only issue this raises is clarity and consistency describing such granular options, where care would need to be taken to ensure that such options were easily understood and didn’t place undue burden on the content creator.
Transparency: It is important that standardised, machine-readable markers indicating the exception be adopted else an interoperable mechanism cannot be implemented at scale matching the volumes of data used by Generative AI. These standards must be open and transparent, so that any member of the public, creator or AI developer can readily establish the status of a data item without reliance on any third party or commercial gatekeeper such as a registry.
It is also important that standardised classes of usage of content are provided in the legislation so that mismatches between creator’s intentions and AI usage do not occur, and that further developments in AI do not render such measures unworkable. This will help ensure a common understanding of what the AI usage is.
Similarly, protection and enforcement measures need to be straightforward, easily implemented and well-policed, in order to gain credibility.
Due diligence: Data is often shared and replicated, in such a way that any opt-out markers associated with it may be accidently removed (‘stripped’) during distribution. For example, opt-out is being expressed in industry using the Coalition for Content Provenance and Authenticity (C2PA) metadata standard also known as ‘Content
Credentials’ [Adobe]. Various technical measures can be implemented to mitigate but not prevent the issue that C2PA metadata is stripped, such as Durable Content Credentials [NSA]. It should be expected that developers act upon any opt-out indicators they received within content, using major open standards such as Durable Content Credentials. But it should not be expected that developers are required to seek out all possible copies of data available on the internet, in order to perform due diligence to determine the opt out status of that data. Such checking could not be performed at sufficient scale, with sufficient accuracy using current technology.
References:
• [Adobe] Adobe Debuts Free Web App To Fight Misinformation And Protect Creators. Forbes Magazine. October 2024. https://www.forbes.com/sites/moorinsights/2024/10/16/adobe-debuts-free-…
• [NSA] Joint guidance on content credentials and strengthening multimedia integrity in the generative artificial intelligence era. January 2025. US National Security Agency. https://media.defense.gov/2025/Jan/29/2003634788/-1/-1/0/CSI-CONTENT-CR…
5. What influence, positive or negative, would the introduction of an exception along these lines have on you or your organisation? Please provide quantitative information where possible.
A well-specified opt-out exception would bolster confidence among our researchers, collaborators, and creative partners, as it clarifies the boundaries of lawful data usage in research.
6. What action should a developer take when a reservation has been applied to a copy of a work?
Developers should respect any clear, machine-readable markers indicating that a work is off-limits for AI training or analysis. At a minimum, they should honour any metadata attached to a data item (so called 'unit level’ opt-out) that indicates the reservation using a widely adopted open standard capable of expressing the same. At a minimum, site-level opt-out instructions (e.g., “no-scrape” flags) on websites similar to ‘robots.txt’ in the context of search engine scraping, should also be honoured.
7. What should be the legal consequences if a reservation is ignored?
Remedies for breaches of copyright are provided in existing law through financial penalties and would presumably be applied for breach of copyright when using data ignoring such a reservation. However, this favours larger commercial operators disproportionately, since it places them in a defacto licensing agreement for any content they wish simply by paying the penalty. In the context of AI model training, it is worth considering an additional remedy of requiring the model developer to retrain the model removing the infringing content. Otherwise, smaller operators such as academic or startups will be in a disadvantaged position, since they could not potentially afford to ignore such a reservation.
8. Do you agree that rights should be reserved in machine-readable formats? Where possible, please indicate what you anticipate the cost of introducing and/or complying with a rights reservation in machine-readable format would be.
Yes. Large-scale AI development demands automated checks. Machine-readable metadata (e.g., in open standards like C2PA [C2PA]) enables frictionless compliance, fostering trust and clarity across multiple platforms. Setup costs vary, but since open standards are unpatented, the implementation overhead primarily involves updating workflows, software, and training developers—likely manageable relative to the benefits.
References:
[C2PA] Coalition for Content Provenance and Authenticity, Technical Specification v2.1. Publisher: Linux Foundation. Available at: https://c2pa.org.
C.2 Technical Standards
9. Is there a need for greater standardisation of rights reservation protocols?
Yes, but without prescribing one single standard in legislation. Multiple protocols exist (e.g., TDMRep [TDMRep], C2PA [C2PA]), and convergence to the latter is likely as cross-industry adoption grows. Government can accelerate adoption by endorsing open, patent-free standards that enable seamless interoperability, rather than mandating a single proprietary approach.
References:
• [TDMRep] TDM Reservation Protocol (TDMRep). W3C Community Report. February 2024. Available at: https://www.w3.org/community/reports/tdmrep/CG-FINAL-tdmrep-20240202/
• [C2PA] Coalition for Content Provenance and Authenticity, Technical Specification v2.1. Publisher: Linux Foundation. Available at: https://c2pa.org.
10. How can compliance with standards be encouraged?
Compliance can be encouraged by making adherence to metadata and rights-reservation markers legally significant, so that failure to observe them raises the risk of infringement claims. This could include measures to deter the removal of such markers. Currently many content platforms (all social platforms) remove metadata of the kind that is likely to emerge as the dominant way of expressing unit level opt-out (e.g. provenance metadata such as C2PA [C2PA]). Although platforms should be able to remove metadata to fulfil requirements around privacy and user choice, they should not routinely remove such metadata, and legislation would be a promising way to encourage compliance.
11. Should the government have a role in ensuring this and, if so, what should that be?
Yes. The government can champion best practices by embedding provenance metadata in its own releases, incentivizing platforms to retain such metadata, and providing clear guidance on compliance. Regulatory frameworks can explicitly penalize deliberate metadata stripping and incentivize preservation, fostering a culture of transparency and respect for creators’ preferences.
C.3 Contracts and Licensing
12. Does current practice relating to the licensing of copyright works for AI training meet the needs of creators and performers?
Current licensing norms are workable but could be improved. Many creators struggle with discovering and negotiating AI-related licences in a timely, cost-effective manner. Emerging provenance and payment tools (e.g., automated micropayments linked to model usage) could significantly enhance creator opportunities for fair compensation. For example, recent research [Balan 2023] at the University of Surrey led DECaDE research centre has explored how images re-used to train Generative AI models may be linked to rights and payment information of their creators, in order to create value in new ways for the creator economy.
Nevertheless, a balance needs to be struck that supports interests of creators on the one hand and AI developers on the other. With the scale of training datasets, the cost of compensating all of the content creators would act as a disincentive to AI developers using UK data. Or, if compensation was affordable, then the amount of money awarded to an individual creator would be vanishingly small. We have seen this take place in sectors like the music industry, where peer-to-peer disrupted traditional models of music distribution, to then be regularised and legalised by the likes of Spotify but at the cost to the content creator to the extent where it is difficult to make money from music production, and live venues are only economically viable at very large scale.
References:
• [Balan 2023] EKILA: Synthetic Media Provenance and Attribution for Generative Art. Balan et al. Proc. CVPR Workshop on Media Forensics. 2023.
14. Should measures be introduced to support good licensing practice?
Yes. Encouraging the use of robust provenance and rights management frameworks can lower transaction costs. By supporting new tools (e.g., automated rights registries, micropayment systems) and educating stakeholders, the government could help standardise fair licensing practices.
15. Should the government have a role in encouraging collective licensing and/or data aggregation services? If so, what role should it play?
Extended Collective Licensing (ECL) has been commonly used in the Nordic countries to address the high demand for data and the challenges around obtaining rightsholder consent. It was introduced in the UK in 2014, and the general practice allows rightsholders who are covered by the collective licensing to opt out if they do not want the licence to apply to their work.
Opting for a Collecting management organisation -based opt-out system for data mining would allow for better decision-making that accurately represents all stakeholders, more flexible and market-driven policies, and greater engagement when designing licensing schemes. This could be achieved, provided the Intellectual Property Office establishes clear and strict transparency measures. The risk of introducing an EU-style opt-out and an ECL-style opt-out is similar—mass opt-outs would undermine the purpose of the opt-out system. However, an ECL-driven opt-out structure would create a platform for negotiation and address challenges related to fair remuneration.
The digitalisation of industries and the rise of artificial intelligence present complex challenges, evolving business models, and shifting content needs. As these models change, the dynamics between stakeholders will also shift, requiring a renegotiation of existing frameworks. CMOs are well-positioned to manage these transitions and adapt to new challenges through the ECL.
ECL licensing is a complex initiative and government incentives should be provided to encourage CMO’s to explore ECL’s as an option.
Although the Soulier v Doke judgement no longer applies after Brexit, it is crucial that the guidance emphasises the importance of ensuring the CMO has effective methods in place to identify extended beneficiaries, so that license-earned revenues can be properly distributed to them.
The lack of clear standards for demonstrating evidence of representation may allow CMOs to determine what qualifies as "significant representation" without adequate oversight. This could lead to misleading claims about the true extent of a CMO's representativeness.
While CMOs are required to secure informed consent from their members, the policy offers flexibility in how this consent is obtained (e.g. through electronic surveys). These methods do not necessarily ensure that all members are adequately informed or fully understand the consequences of agreeing to the ECL scheme. Additionally, members whose works are not included in the scheme, but who may still be financially impacted, might not be adequately consulted.
The new 2025 ECL guidance policy permits CMOs to conceal the reasons why non-members opt not to participate in the scheme, even though these objections may indicate significant issues. This lack of transparency might lead to an ECL scheme being approved without thoroughly addressing the concerns of those outside the system.
The IPO should take measures to address these gaps by involving itself as impartial observers of CMO discussions, assessing the quality of decision-making.
C.4 Transparency
17. Do you agree that AI developers should disclose the sources of their training material?
Although in academic research it is often desirable to disclose the source of training data, the University of Surrey recognises that full disclosure training data may conflict with commercial confidentiality and trade secrets, particularly for spin-outs and larger enterprises.
The University of Surrey supports a system in which AI developers attest to having lawfully obtained and properly licensed data for AI training – including respecting any rights reservations. This approach strikes a balance between reproducibility, accountability and preserving the competitive edge that unique data selections may confer to AI models. There will be exceptions to this approach. In the case of AI development that is shared as open source, then the details of training datasets used to create the AI model should be published alongside the AI model, although the method by which the data was used to train the AI may not be required. In the case of AI models used in safety critical applications, then the datasets used to train the model, and the architecture of the training approach should be made available but perhaps not publicly. For example, there could be a role here for a trusted third party such as the UK’s AI Security Institute to be a repository to records of AI training data used for particular models.
18. If so, what level of granularity is sufficient and necessary for AI firms when providing transparency over the inputs to generative models?
A practical model would emphasize disclosing the overall nature and licensing status of the training data rather than every individual source. Summaries of data provenance— along with clear indications of how opt-out requests were handled—could offer adequate transparency. Such summaries enable regulators or third parties to verify compliance without forcing developers to reveal proprietary details or confidential data and might be enabled through open provenance standards such as C2PA. Exceptions may need to exist for safety critical applications and other special cases.
19. What transparency should be required in relation to web crawlers?
At a minimum, developers should respect site-level “no-scrape” flags. Tools or frameworks that reference open standards for expressing such flags (like the defacto standard ‘robots.txt’ or emerging ideas such as TDMRep) would help site owners set consistently respected usage permissions.
22. How can compliance with transparency requirements be encouraged, and does this require regulatory underpinning?
It is anticipated that existing regulatory powers would be sufficient to encourage transparency, if properly applied and policed by the regulator.
C.5 Wider clarification of copyright law
24. What steps can the government take to encourage AI developers to train their models in the UK and in accordance with UK law to ensure that the rights of right holders are respected?
Publishing a clear and consistent approach to AI regulation, at the earliest possible date, will attract AI developers on a global basis – uncertainty in regulatory approach is probably the biggest disincentive to training models in the UK. In addition, making available AI training datasets for various applications, ideally only useable in the UK, would also represent a significant attraction.
25. To what extent does the copyright status of AI models trained outside the UK require clarification to ensure fairness for AI developers and right holders?
This represents a significant challenge to both content creators and AI developers within the UK. Encouraging non-UK AI models to be compliant with UK copyright law, even if trained overseas, would go some way towards ensuring a level playing field.
C.6 Encouraging research and innovation
28. Does the existing data mining exception for non-commercial research remain fit for purpose?
The exception may have to be modified, depending on the adoption of some of the measures suggested herein. For example, introduction of granular opt-outs might include a “don’t use for research” flag which would have to be observed.
29. Should copyright rules relating to AI consider factors such as the purpose of an AI model, or the size of an AI firm?
Yes. Where applications relate to safety, security and privacy, the copyright rules may have to be amended appropriately.
D. AI Outputs
D.2 Policy Options
30. Are you in favour of maintaining current protection for computer-generated works? If yes, please explain whether and how you currently rely on this provision.
Yes, it is critical for the UK to maintain current protection for computer generated works (CGWs) for the benefit of the UK’s economy, AI ambitions, and international competitiveness.
CGWs increasingly have commercial value. Protection of these works with copyright is a vital incentive for people and businesses to invest in the development and use of creative AI systems. In turn, this benefits not only the UK’s creative industries, but the UK public by providing encouragement for the creation of new works, as well as the dissemination of those works.
aCDPA 9(3) has not yet been terribly impactful in the UK, but that is because until very recently CGWs have not had meaningful commercial value. They are now starting to, but given the speed at which AI capabilities are improving and industry adoption is increasing, CGWs are going to have far greater value in 5 and 10 years from now. Copyright protection will be increasingly critical as AI systems continue to improve with respect to their capabilities to output CGWs, and as creative industries such as the film and music industries increasingly rely on the use of AI. In the meantime, to encourage the necessary investments in creative AI systems there needs to be a legal framework today that provides adequate protection – and as there currently exists in the UK.
By contrast, absent such protection, CGWs may pass into the public domain in which case they cannot be effectively monetized, and thus there is minimal incentive to create them in the first place or invest in their dissemination.
For an extended review of the benefits of protecting CGWs, and other questions asked in this Section D1&2, please see the following research conducted at University of Surrey:
Ryan Abbott and Elizabeth Rothman, Disrupting Creativity: Copyright Law in the Age of Generative Artificial Intelligence, Florida Law Review (2023)
31. Do you have views on how the provision should be interpreted?
Please see the following research conducted at University of Surrey:
Ryan Abbott, Artificial Intelligence, Big Data and Intellectual Property: Protecting Computer-Generated Works in the United Kingdom, In RESEARCH HANDBOOK ON INTELLECTUAL PROPERTY AND DIGITAL TECHNOLOGIES (Tanya Aplin ed., 2020)
32. Would computer-generated works legislation benefit from greater legal clarity, for example to clarify the originality requirement? If so, how should it be clarified?
It may be helpful to clarify that the originality requirement is no bar to protection of CGWs in the UK. Dicta from European cases about originality using human-centric terms is not applicable to cases involving CGWs. Those cases did not involve CGWs. Moreover, the UK has a plain statutory framework for protecting CGWs in the form of CDPA 9(3) that such case law would not override. Parliament has clearly spoken on this issue. Unlike the UK, most European jurisdictions do not have explicit protection for CGWs.
33. Should other changes be made to the scope of computer-generated protection?
CGWs should be designated as CGWs rather than applying deemed authorship to the work’s producer. It is unfair for a person to take credit for work done by an AI system. It is not unfair to the AI, which has no interest in being acknowledged, but it is unfair to traditional authors to have their works equated to someone simply asking an AI system to generate a creative work.
35. Are you in favour of removing copyright protection for computer-generated works without a human author?
No, primarily for the reasons discussed in the answer to Q30 above.
In addition, if copyright protection is removed for CGWs, as a practical matter, individuals producing CGWs are likely to obfuscate about the origin of these works.
36. What would be the economic impact of doing this? Please provide quantitative information where possible.
The economic impact would be to eliminate the most important financial incentive to create and disseminate new works. As a result, the UK creative industries would be disadvantaged compared to industries in other jurisdictions that do allow protection of computer-generated works.
D.6 Digital replicas and other issues
43. To what extent would the approach(es) outlined in the first part of this consultation, in relation to transparency and text and data mining, provide individuals with sufficient control over the use of their image and voice in AI outputs?
We believe that individuals should have strong rights to protect their biometrics, including visual appearance, voice, and other representations of their person. This might be a case where Option 1 should be applied. This might be applied, for example, to the data that is acquired through devices like Meta/Ray-Ban sunglasses, where your image might be captured by a device wearer, without your knowledge or consent, and shared with the company and used for AI training.
D.7 Other emerging issues
45. Is the legal framework that applies to AI products that interact with copyright works at the point of inference clear? If it is not, what could the government do to make it clearer?
The EU legislation in place for Copyright is not specific about the kinds of AI data may be used for, or the specific action (training or inference) that it may be used for. This is problematic because it places in a grey area the potential use of an image in a digital editing tool, since such tools are trending toward the use of AI for routine image manipulations. Yet running inference on an image in such tools might be prohibited by AI opt-out. Similarly, most content recommendation and search systems will extract descriptors from content in order to make it discoverable. This is usually a net gain for creatives yet might be legally questionable given a blanket TDM opt-out. This is one reason why the University believes greater specificity and granularity is required in opt-out legislation. Nevertheless, there is an inherent challenge that the rapid pace of change in the field of AI means that legislation is often catching up at a slower pace.
A question to consider here is would the UK forbid access to AI that had been trained on what we consider to be unacceptable terms to the content creators?
46. What are the implications of the use of synthetic data to train AI models and how could this develop over time, and how should the government respond?
Using synthetic data for AI training can be of significant benefit in some application areas. However, they can also pose risks to model accuracy and reliability, especially when widely shared and inadvertently subsumed into other training datasets, a phenomenon sometimes referred to as “model collapse,” which occurs when generative models progressively re-train on their own outputs. This may dilute originality and utility over successive training cycles, ultimately harming the quality and potential of AI systems. As more online content includes AI-generated material, safeguarding datasets against such inadvertent self-contamination becomes increasingly important. Provenance standards (e.g., C2PA [C2PA]) can help AI developers distinguish authentic from synthetic media and selectively curate training sets. Government guidance on metadata preservation and content labelling—coupled with support for open-source or industry-led registries—may help ensure the integrity of training data, thereby fostering more robust and trustworthy AI development in the UK.

- March 2025: 30 UK scientists swapped places with politicians and civil servants, exploring the world of politics as part of the annual Royal Society Pairing Scheme. CVSSP’s Professor John Collomosse participated in the Scheme, working directly with the Department for Science, Innovation and Technology's team for policy and capability in AI and Disinformation. This vital initiative helps ensure evidence-based policymaking. Professor Collomosse's expertise, honed through DECaDE and his work in the formation of the Content Authenticity Initiative, will be invaluable. A fantastic opportunity to amplify our research for the public good.
- March 2025: The Alan Turing Institute's new report, Securing the UK’s AI Ecosystem, represents a significant step towards shaping the UK's AI landscape. We're delighted that PAI's Dr Andrew Rogoyski was asked to contribute his expertise. His comments and suggestions have helped to inform this timely, must-read document.
- January 2025: PAI welcomed a delegation from the Department for Education (DfE), led by Julia Kinniburgh, Director General of the Skills Group. The group was hosted by our Director, Professor Adrian Hilton, and Co-Director, Professor Yi-Zhe Song. Professor Hilton provided an overview of how Surrey is leveraging its 40-year heritage to embrace the ambitions set out in the AI Opportunities Action Plan.
- January 2025: Our experts’ written evidence was cited 11 times in the UK House of Lords Communications and Digital Committee's report on AI and creative technology scaleups, which highlights the critical need to support UK AI and creative tech startups. Our citations demonstrate the impact of our research and our commitment to fostering a thriving AI ecosystem.
- December 2024: PAI's Dr Erick Sperandio was invited by the Ministry of Foreign Affairs and the Ministry of Science, Technology and Innovation of Brazil, to contribute to the International Seminar: “Artificial Intelligence and Climate Change”.
- September 2024: at the annual conference of the ruling Labour Party, PAI, with other partners, presented a Cultural and Creative Industries Pavilion, coordinated by Creative UK. PAI’s Dr Andrew Rogoyski spoke on aligning the AI opportunity with policy which equally values human creativity and development and application of artificial intelligence. During the conference, the Pavilion hosted events run by more than 40 partners across the arts and culture sector. The PAI team enjoyed stimulating discussions and debates around the creative and cultural industries, with a special focus on AI. Follow us on LinkedIn or X for live updates.
- August 2024: PAI’s Dr Andrew Rogoyski, with Professor Alan W. of the Surrey Centre for Cyber Security issued a paper in response to the UK Government’s call for views on the cyber security of AI: “As [AI] adoption continues to grow across society, we must ensure that end-users are protected from cyber security risks.” Jonathan Berry, Viscount Camrose, Minister for AI and Intellectual Property.
- May 2024: "Thank you for the very important advice you gave me and members of my committee during this parliament. We had a big enquiry into the governance of AI and our visit... to your Institute for People-Centred AI [PAI] right at the beginning of our thinking was very important in shaping the direction of enquiry. Really grateful for that." Rt Hon Greg Clarke MP, Chair of the House of Commons Science, Innovation and Technology Committee, video here: https://lnkd.in/e-TWZzig.
- April 2024: PAI led a workshop at the British Embassy Bangkok as part of the 'Advancing AI Agenda in Thailand' project funded by the UK Foreign, Commonwealth and Development Office (FCDO). PAI’s Erin Chao Ling, Andrew Rogoyski and Mikolaj Firlej led dynamic discussions with Thai regulators and policymakers. This represented a leap forward between the British and Thai governments in fostering international collaboration and opening up new frontiers in the ever-evolving world of Artificial Intelligence.
- April 2024: PAI’s Dr Andrew Rogoyski was entered in Hansard, the official report of the UK Parliament. This followed his referencing by the Labour Shadow team on accelerating the UK’s position on AI regulation, during last week's questions to the Secretary of State for Science, Innovation and Technology. This was significant evidence of impact on policy engagement.
- April 2024: PAI Fellow Prof Melissa Hamilton spoke at the Westminster Legal Policy Forum on Next Steps for AI Technology in the Criminal Justice System.
- March 2024: AI and Democracy: 3 Months to Save Democracy: an influential PAI election report was published, and widely covered by media. Authors were Drs Andrew Rogoyski, Bahareh Heravi, Roula Nezi and Daniele Albertazzi.
- March 2024: PAI made significant contribution on ethical vision for AI to the House of Lords’ Communications and Digital Select Committee inquiry on Large Language Models and Generative AI. Sabine Braun, Andrew Rogoyski and Constantin Orasan contributed topical evidence, including the impact of the first AI regulation coming soon.
- March 2024: PAI was recognised in the Government’s response to the AI regulation white paper following its contribution of written evidence and engagement in the run-up to the Government’s AI Safety Summit. The report also highlighted the importance of the 24 new UKRI-funded AI Centres for Doctoral Training: PAI is home to the CDT in AI for Digital Media Inclusion.

- January 2025: Dr Simon Hadfield, with Surrey colleagues, introduced a multimillion-pound research project, called SustaPack, that aims to overcome manufacturing challenges for the next generation of sustainable, paper-based packaging for liquids. Backed by a £1 million grant from the Engineering and Physical Sciences Research Council (EPSRC) as part of UKRI’s co-investing programme, packaging technology company Pulpex Ltd has joined forces with the University of Surrey to refine its manufacturing processes to provide a viable solution to plastic pollution.
- December 2024: PAI’s Professor Richard Bowden secured £8.45m award for his project to build a sign language AI model, SignGPT. The five-year project, funded by the UK Engineering & Physical Sciences Research Council, will develop tools that can automatically translate spoken language into realistic sign language videos, and vice versa. Surrey will work alongside the University of Oxford, the Deafness Cognition and Language Research Centre at University College London, key Deaf stakeholders, and the Deaf community.
- December 2024: PAI Fellows Professor Mark Plumbley and Dr Bing Guo are key figures in two new UK Research and Innovation engineering networks tackling critical engineering and environmental challenges. These networks are part of six transdisciplinary research projects at UK institutions, each receiving a share of a £10 million EPSRC investment. The two projects to which PAI scientists are making significant contributions are: * Professors Mark Plumbley and Abigail Bristow: 'Noise network plus: engineering a quieter future.' * Dr Bing Guo: 'Better water for all: re-engineer water engineering for equitable and resilient access to high-quality water for future generations.'
- September 2024: UKRI Centre for Doctoral Training in AI for Digital Media Inclusion - a transformative AI Training programme designed with inclusion for all at its heart. The Government officially announced that the University of Surrey and the StoryFutures unit at Royal Holloway, University of London, will be the home of a new UKRI Centre for Doctoral Training (CDT) in AI for Digital Media Inclusion. The programme commenced in September 2024 and its first cohort has enjoyed numerous high-level visits, instruction, events, workshops and supervisory input.
- July 2024: PAI Launches UKRI fully funded PhD studentship in Multimodal AI foundation models for smart predictive and prescriptive maintenance, supervised by PAI’s Dr Erick Sperandio.
- July 2024: PAI announces UKRI funded PhD Studentship in Designing AI for Home Wellbeing through Participatory Design, supervised by PAI’s Professor Philip Jackson, Dr Sarah Payne and Dr Emily Corrigan-Kavanagh. May 2024: PAI’s Dr Bahareh Heravi partnered with the BBC in a major research project to develop responsible use of AI. The Bridging Responsible AI Divides (BRAID) Fellowships are part of the BRAID programme, led by the University of Edinburgh, in partnership with the Ada Lovelace Institute and the BBC. The £15.9 million, six-year programme is funded by the Arts and Humanities Research Council, part of UK Research & Innovation.
- January 2024 Human health: UKRI EPSRC People-Centred Mammogram Analysis research award designing AI solutions in healthcare to work alongside clinicians complementing their expertise to improve patient outcomes.
- January 2024: AI Digital Accessibility: PAI awarded multi-million-pound Leverhulme Doctoral Scholarships grant. The new Leverhulme Doctoral Scholarships Network for AI-Enabled Digital Accessibility – ADA – will be established at Surrey after the Leverhulme Trust awarded a grant of £2.15m for the eight-year project.
January 2024: AI Creative Digital Accessible: AI named core partner in £51m CoSTAR National Lab, focusing on R&D in Creative Technology. CoSTAR, funded by the Arts and Humanities Research Council, aims to put the UK at the forefront of applied research in AI for the creative sector, ensuring global competitiveness in screen and performance industries. PAI will lead Creative AI research and training within CoSTAR, developing next-generation AI-powered storytelling experiences and technologies.
Press releases
Read our latest news stories about everything we are doing around AI here at Surrey.








