
Creative vision and sound
Creating machines that can see and hear
Creative Vision focuses on machine perception for creative technologies, specialising in 4D immersive VR content production, performance capture and video-based animation for film and games.
Creative Sound works on spatial audio and machine audition, developing audio signal processing technology related to sound recognition and immersive audio experiences.
Research leads
Creative vision

Professor Adrian Hilton
Director Surrey Institute for People-Centred AI and the Centre for Vision, Speech and Signal Processing

Professor John Collomosse
Professor of Computer Vision and AI | Director DECaDE: UKRI/EPSRC Centre for the Decentralised Digital Economy

Dr Jean-Yves Guillemaut
Senior Lecturer in 3D Computer Vision
Creative sound

Professor Wenwu Wang
Professor in Signal Processing and Machine Learning; Associate Head (External Engagement), School of Computer Science and Electronic Engineering; Core AI Fellow, Surrey Institute for People Centred AI

Professor Philip Jackson
Professor in Machine Audition
Overview
The last 20 years have seen a move from manual to automated digital processes for film and TV production, kick-starting a boom in virtual reality (VR), augmented reality (AR) and 3D spatial audio. Our Centre is at the forefront of research in all three fields.
Visual effects are used to bring stories to life, not only in sci-fi blockbusters such as Star Wars, but for period dramas, live action sports broadcasts and many other types of entertainment content. The ability to change an actor’s eye colour or add in background details using visual processing software has revolutionised the film production industry. Over the past two decades, the processes used to achieve these effects have become increasingly sophisticated.
Professor Adrian Hilton, Director of CVSSP, explains: “Twenty years ago, film was a highly labour intensive industry, with everything being done manually. Computer vision has introduced AI enabled creative tools which support artists and increase creative freedom. This accelerates their work flow and has opened up the potential to create amazing visual effects – although it will never be a matter of just clicking a button.”
Capturing reality

One area where we have helped to make huge strides is in 3D visual effects. Pioneered by our Centre in the mid-1990s, 3D video capture did something that would transform animation: It captured the real appearance and movements of people and animals enabling highly realistic animations to be created.
“It’s incredibly difficult to animate a person to look real, but using the technology we’ve developed you can film an actor and use that data to create incredibly lifelike animations,” says Professor Hilton.
“An actor’s performance is the most precious element of a film so it’s about preserving that as much as possible while also allowing artists to manipulate it to enhance the story – transforming the actor to look like Gollum in Lord of the Rings, for example, but retaining his performance.”
The 3D shape capture technology we developed was quickly picked up by industry. Our first projects in this area included developing animations with major production houses for the BBC series Walking with Dinosaurs with both Jim Henson’s ‘Creature Shop’ and Framestore. Through a Royal Society Industry Fellowship, Professor Hilton collaborated with Framestore to develop tools that enabled sophisticated techniques to create ‘4D Digital Doubles’ of actor performance ’ – a system that could capture highly realistic 3D shape over time for the face or body. This technology contributed to production of digital actor performance in feature films such as Gravity.
Oscar-winning Surrey spin-out

Imagineer Systems, which was founded by CVSSP Lecturer Dr Phil McLauchlin with undergraduate student Allan Jaenicke in 2002, went on to win a technical Academy Award ten years later for its groundbreaking ‘mocha: Planar Tracking’ system. This visual effects solution has been used on major feature films including The Hobbit, Black Swan, The Amazing Spider-Man, The Wolf of Wall Street and the Harry Potter series.
Imagineer’s CEO John-Paul Smith comments: “Imagineer was born out of CVSSP, grew up in the Surrey Technology Centre and continues to work with the University today. Collaborating with academics at the top of their field has identified where advances in the state of the art can help us deliver superior solutions and supported innovative developments of our core technology.”
4D machine perception

The rapid growth of machines interacting with our real world has led to an increasing demand for machines to understand what they see. Our world is inherently four-dimensional, comprising of three-dimensional objects, such as people and animals, moving in time. Developments in 4D machine perception are important to enabling autonomous systems in the entertainment, healthcare, assisted living, animal welfare and security industries.
We have been working on 4D vision for the past two decades. This includes sophisticated multi-camera indoor and outdoor capture systems; advanced algorithms to model complex scenes in 3D; methods to align these models in time (4D); creating photo-realistic models and finally rendering them in free-viewpoint video for applications in sports broadcast or in virtual reality.
Dr Armin Mustafa, has been awarded a 5-year Royal Academy of Engineering Fellowship to explore 4D machine perception technology which will allow computers and mobile devices to understand the world we live in. Dr Mustafa says: "Smart machines have quickly become a feature of our day-to-day lives. It’s important to progress 4D vision by exploiting advances in machine learning, that will be at the core of future smart machines so they can ultimately work safely alongside us.”
‘Kinch and the Double World’

The growth of virtual reality (VR) has been one of the driving forces behind recent projects within our Centre. Meeting a demand for evermore innovative ‘experience’ applications, we have collaborated with Foundry and local VR company Figment Productions, the creator of ‘Derren Brown’s Ghost Train’ at Thorpe Park and ‘Galactica’ at Alton Towers. This collaboration funded by InnovateUK, researches, develops and demonstrates new methods of producing immersive virtual reality experiences that combine the realism of live-action video with freedom of movement, previously only possible with computer-generated imagery techniques.
One project, ALIVE, has seen us collaborate with visual effects software developer Foundry and production company Figment Productions to develop ‘Lightfield’ video technologies that create digital doubles of actor performance in 360° VR experiences, with the visual quality of video and the interaction of computer games.
‘Kinch and the Double World’, an output from the ALIVE project, is a live-action cinematic VR experience which allows viewers to step into the virtual world. The film is set in Victorian London, and tells the story of an orphan who gets caught up in a stage magician’s trick and ends up being transported to a magical world. It has been showcased at film festivals and academic conferences including RainDance and SIGGRAPH.
Dr Marco Volino says: “With ALIVE, we wanted to create technology that allows audiences to really step into a scene. Imagine swinging between sky-scrapers as Spider-Man or being on the Millennium Falcon – ALIVE brings us closer to this reality. This is made possible by the advances we have made in 4D vision.”
Game changer: Nurturing collaborations with Guildford’s Game industry

We not only pioneer groundbreaking technologies that are powering futuristic video, games and films, we are also playing a pivotal role in promoting the digital media industry itself.
In 2015, our Centre and the Digital Media Arts Department at Surrey joined forces with the trade body UKIE (UK Interactive Entertainment) and technology law specialist CRS (Charles Russell Speechlys) to launch a new initiative fostering collaboration with the local games industry. G3 (Galvanising Guildford Games) aims to promote the internationally-renowned Guildford games hub. With over 60 games studios in the area and known as the “Hollywood of the UK Games Industry”, G3 enables collaboration between world-leading studios, artists, developers and sector-related businesses along with academic experts specialising in the creative industries.
The G3 initiative has assisted Surrey in establishing partnerships, securing £3m of government funding for collaborative projects, and has facilitated students’ access to leading games companies via networking events and placements, helping to provide a stream of talented engineers who will help shape the future of the games industry. By collaborating with some of the biggest UK players in this sector, we have led many exciting projects pioneering technologies such as video-based performance capture.
Developing performance capture

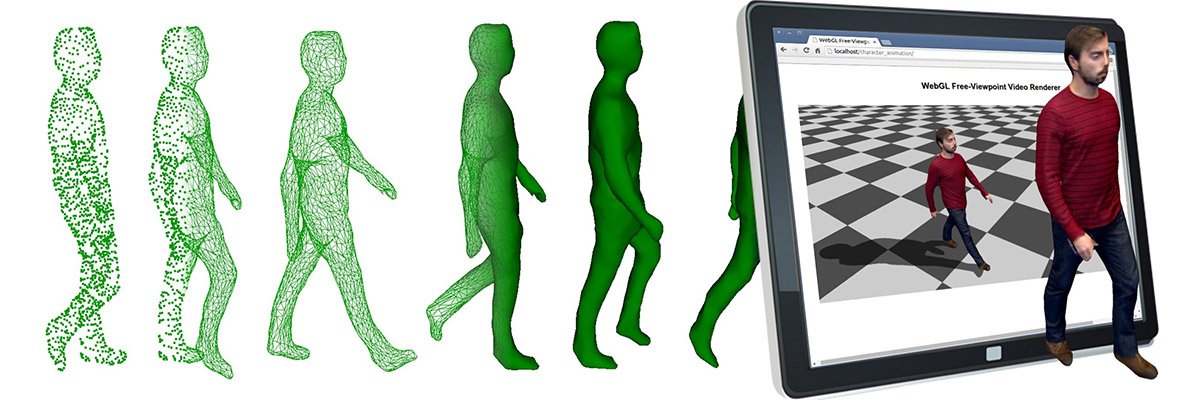
New 3D performance capture technology requires no optical markers, or specialised infrared cameras and can be used indoors or out, giving filmmakers and video-game artists unprecedented flexibility. This overcomes the limitations and restrictions of existing motion capture technologies enabling high-quality animation production for film, games and VR.
Over the last decade, we have been at the forefront of research in this new approach to capturing live full-body performers outdoors. Imagine a world where you are not restricted to a sound stage with expensive cameras to accurately capture a performance for a video game or CGI character in a blockbuster film. With this technology, you can capture the performance of a subject in a variety of locations using a simple, low-cost set up. Dr Charles Malleson comments: “Surrey has now developed real-time marker-less performance capture which is lower cost, quicker to deploy, and more flexible in terms of capture environment than traditional systems – something that’s of great interest to the film and game production industry.”
Sketch based search

The deluge of visual content online, and the shift toward its consumption on mobile devices that lack a keyboard, demand new visual ways to search beyond typing text into a box on a search engine (e.g. Google).
We have pioneered Sketch-based Image Retrieval (SBIR) technology that enables users to find the images they want by simply drawing with a mouse or finger. Unlike photo based search, users do not need an example of the visual content they wish to find – only a picture in their mind’s eye. Sketch is a challenging scientific problem, because a drawing is ambiguous. We train an AI to help understand sketched search queries in a similar way to a human, using neural networks to help find the right content.
Our team collaborated with Adobe Research in Silicon Valley to explore how the technology could be used to search millions of artworks on the Internet. The work led to a string of high profile publications at CVPR; the premier international conference for Computer Vision. Dr Tu Bui, whose recently awarded PhD focused on SBIR, noted “The advent and popularity of touchscreen based technology, such as tablets and smartphones makes SBIR a timely research area.”
CVSSP and the BBC: Two decades of partnership
Since 1999, we have worked closely with the BBC, leading to a range of innovations in 3D video production, video analysis and spatial audio which many TV viewers will be familiar with. The BBC collaboration on 3D video production began when Professor Adrian Hilton (Director of CVSSP) and Professor Graham Thomas (lead of the Immersive and Interactive Content section at the BBC) collaborated on Prometheus, a research project aimed at creating animated characters automatically from video.
This work led to the development of a sports graphics product which is used by the BBC and other broadcasters around the world for football and rugby analysis. Professor Thomas explains: “The quality of the characters we produced in the early days was quite simple: they all conformed to a standard shape but the width and height of the body could be adjusted. Since then we’ve done a lot of work with CVSSP which has really revolutionised the way we capture human motion from video.” One project, iview, aimed to bring character capture technology normally used in a studio to a very large scale – a football pitch. This was a challenging project which involved rigging numerous cameras, capturing footage, and processing it quickly enough to get a clip ready to use on Match of the Day.
The BBC established the Audio Research Partnership in 2011 with CVSSP as the lead University for audio-visual research. This subsequently led to the UK flagship ‘S3A: Future Spatial Audio’ project collaboration led by Professor Hilton. S3A has combined spatial audio reproduction with visual understanding of the listener and their environment to enable immersive listening experiences at home.
We have recently been selected by the BBC as a lead partner in the Data Science Research Partnership to collaborate on future AI technologies for media production and delivery of new audience experiences. The partnership between our Centre and the BBC extends to teaching as well as research. Graham Thomas, also a visiting professor at Surrey, believes that collaborating with academia is vital for broadcasters like the BBC. He says: “It means we can tap into a much wider set of potential collaborators, expanding our team from four or five people to 20 or more. Working with academia gives us the opportunity to take a longer term view of things, exploring technology that may not go anywhere – but may lead to a game-changing solution. We wouldn’t be able to take that risk without academia.”
Making sense of sounds – creating machines that can ‘hear’

Imagine yourself on a street corner. When you close your eyes, you can hear traffic, footsteps, doors closing, people’s conversations. Without needing to look, you know where you are. If we want to build AI systems that can sense what is happening around them, then they need to have a sense of hearing too.
We are investigating new signal processing and machine learning methods to analyse sounds and develop a general-purpose audio-tagging system to simulate the auditory function of a human. This improves a machine’s awareness of sounds, enabling better decision making that could be used for security surveillance, digitising content in archives, improving the search facilities in recorded audio-visual material, environmental monitoring, assisted living and situational awareness in defence.
Historically, sound work in AI has focused on speech and music recognition, however we are pushing the boundaries and researching real-world sounds. This is challenging, since like humans, machines face the ‘cocktail party problem’, trying to hear a specific sound or conversation. This may not be the loudest sound in the room, since real-world sounds are composed of many sounds mixed together. Sound recognition allows a machine to identify what each specific sound is and to search through sound databases so that it can understand them. It is only then that we can say that the machine has a true sense of hearing.
Creating a community

Until recently, there was no single dedicated research community for those working in the field of real-world sounds. In order to be successful, many examples of datasets need to be gathered to train AI systems, so we have been building an international collaboration of projects to research this expanding area. Long-standing collaborators include Tampere University of Technology (Finland), Google Research (USA) and Audio Analytic (UK).
Professor Mark Plumbley says: “We have been organising data challenges and workshops to bring leading international researchers together to learn from each other and to solve these difficult problems.”
In 2013, researchers gathered for the first time at a small poster presentation; this initiative grew to a two-day workshop with 150 attendees that we hosted in 2018. The number of submissions to these competitions and challenges has also grown – from 22 in 2013 to over 600 in 2018.
At one of these challenges, we outperformed major international corporations and global university groups. The Kaggle Freesound Audio Tagging Challenge, part of the DCASE 2018 Challenge, required competitors to create a machine that could identify and understand everyday sounds. We ranked 3rd out of over 550 systems. This came after a first-place ranking in the 2017 challenge.
Spatial audio coming to a living room near you

In tandem with advances in 3D visual content, we are also leading advances in 3D audio for the creation of immersive VR experiences.
In 2013, we were awarded a five-year EPSRC Programme Grant worth £5.4 million to deliver a step-change in immersive audio. S3A: Future Spatial Audio for Immersive Listener Experience at Home is a major UK research collaboration between internationally leading experts in 3D audio and visual processing at the Universities of Surrey, Salford and Southampton together with the BBC.
S3A aims to enable listeners to experience the sense of “being there” at a live event, such as a concert or football match, from the comfort of their living room through delivery of immersive 3D sound to the home using object based content. Although visual content in film, TV and games has undergone a transformation from 2D to 3D and 4D in the past decade to enable greater visual engagement, the development of 3D audio content is less evolved. Existing technology needs to meet consumers requirements wanting to experience live events, without having to set up loudspeakers in precise locations around their living rooms, or to control their room acoustics.
Professor Adrian Hilton comments: “The partnership has worked to unlock the creative potential of 3D sound to provide immersive experiences to the general public at home or on the move. S3A has pioneered a radical new listener centred approach to 3D sound production that can dynamically adapt to the listeners’ environment and location to create a sense of immersion. S3A is changing the way audio is produced and delivered to enable practical high quality 3D sound reproduction based on listener perception”.
The Turning Forest: Immersive audio bringing a virtual fairy tale to life

The Turning Forest pushes the boundaries of what is possible with VR and immersive sound by combining VR with an object-based spatial audio soundtrack developed in S3A to create an enchanting, immersive experience for the user. Captivating audiences around the world, this interactive virtual reality fairy tale is aimed at better understanding the potential of immersive audio to inform, educate and entertain.
Since its premiere at the Tribeca Film Festival in New York, The Turning Forest went on to win the TVB Europe Award for Best Achievement in Sound and was a finalist for Best VR experience of the 2017 Google Play Awards.
“The spatial audio technology we are developing in the S3A project aims to create a more realistic and immersive experience for people in their own homes – without the need for complex speaker set-ups. This work aims to completely change the way home audio is produced and delivered in the future”. Professor Adrian Hilton, Director of CVSSP.
The Vostok-K Incident

The Vostok-K Incident, an S3A specially created science fiction story, was designed to specifically take advantage of additional connected devices available to users. The S3A researchers used a technology called “object based media” to flexibly reproduce audio, regardless of what devices people connect to or how these are arranged. In fact, the more devices that are connected, the more immersion the listener experiences by unlocking surround sound effects as well as extra hidden content.
“Sound has the power to draw you inside a story. The new system that’s been developed removes these requirements by using devices that are already available and adding the flexibility to adapt to changing conditions” Dr Philip Jackson.
“This is a big step forward to S3A’s goal and the future of spatial audio of bringing exciting and immersive experiences to listeners at home without specialist audio devices or setups” Professor Adrian Hilton, Principal Investigator of S3A.
Latest research news
Research projects
- Visual Media Platform (EPSRC)
- BodyShape 'Body Shape Recognition for Online Fashion' (EPSRC)
- Royal Society Industry Fellowship with Framestore Digital Doubles: From real-actors to computer generated digital doubles
- S3A: Future spatial audio for an immersive listener experience at home
- Video-based capture, reconstruction and rendering of people
- VisualMedia
- Total Capture for real-time animation (Innovate UK)
- ALIVE ‘Live Action Lightfields for Immersive Virtual reality Experiences’ (Innovate UK)
- RE@CT - Immersive production and delivery of interactive 3D content (EU IST)
- SCENE - Novel scene representations for richer networked media (EU IST)
- SyMMM - Synchronising multimodal movie metadata (TSB)
- i3Dpost - Intelligent 3D content extraction and manipulation for film and games (EU IST)
- i3Dlive - Interactive 3D methods for live action media (TSB/EPSRC)
- iview - Free-viewpoint video for entertainment content production (TSB/EPSRC)
- VBAP - Video-based animation of people (EPSRC)
- Making Sense of Sounds
- Audio Commons
- Musical Audio Repurposing using Source Separation)
- MacSeNet: Machine Sensing Training Network
- Sparse Representations and Compressed Sensing
- Signal processing solutions for the networked battlespace
- Personalised Content Accessibilities for hearing impaired people for connected digital single market.




